To improve the performance of a statistical production process by managing and optimising the data validation process, a description of the data validation process life cycle would be helpful.
First, the process is both dynamic and complex. Adapting validation rules may affect not only the scope of one dataset or one statistical domain, but also that of all statistical domains. For instance, when optimising the effectiveness and efficiency of the validation rules, their assessment from last time, relationships with indicators etc. should be taken into account. Second, the process should be viewed as an integral part of the whole statistical information production process.
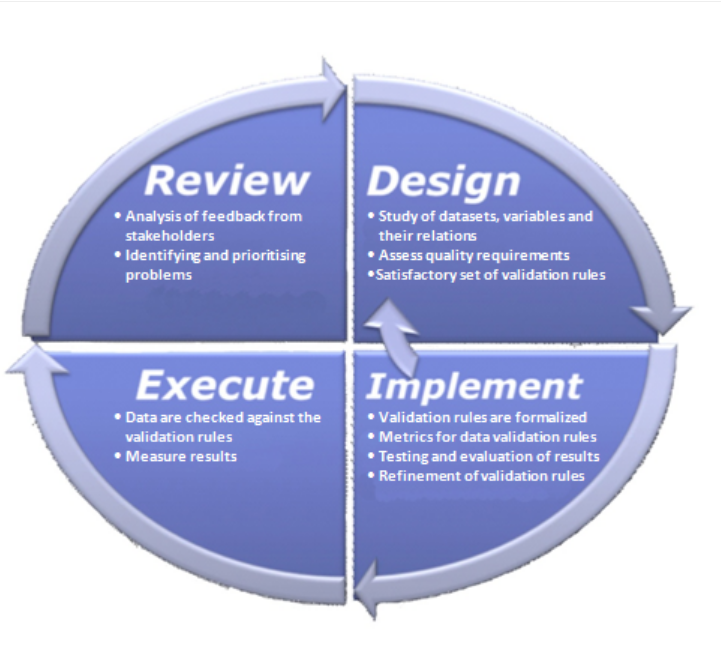
The data validation life cycle involves the activities directly linked to each statistical domain for the definition and execution of data validation. This cycle starts by designing the data validation process for the statistical domain or inter-statistical domain, with an overall study of the datasets, variables and their relationships to find a list of suitable and effective validation rules. In the implementation phase, these validation rules are described in common syntax, formalised, tested and refined, discussed and evaluated by stakeholders. During the execution phase, data are checked against the rules; with validation results measured and quantified. These outputs are reviewed to improve the list of validation rules.
The data validation process is an integral part of the whole statistical information production process. Validation tasks and controls are performed by several stakeholders with a wide range of responsibilities. The data validation process life cycle should provide a clear and coherent allocation of actions and responsibilities to ensure the highest level of performance, while reducing the number of possible errors. However, it may be difficult to allocate responsibilities to each phase of the data validation life cycle due to the complexity of the data validation procedure and because this is closely related to the specific structure of the organisation.
Designing validation rules and rule sets for a dataset involves distributing validation tasks in the statistical production chain to be proposed to the decision-making structures. This distribution of responsibilities should be designed based on the principle of ‘the sooner the better’ as it is commonly agreed that the cost of fixing data errors in terms of resources, time and quality is lower the closer it is to the data source.
For further details on the phases of the validation cycles, you may consult Chapter 8 in the ESS Handbook on Methodology for Data Validation.