New quality aspects along the data pipeline
Contrary to the quality dimensions of traditional data sources such as survey data or admin data, quality aspects for new data sources such as web scraped data still need to be developed.
The traditional quality dimensions such as accuracy and reliability, timeliness and punctuality or comparability and coherence have retained their importance. But the circumstances under which these quality dimensions are measured, and sometimes also the concepts and definitions of how to measure them, change when working with web-scraped data. For example, „comparability over time“ in the case of web scraped data is very much dependent on stable access to the data source; failed scraping processes negatively affect the comparability over time.
Further, the traditional quality dimensions are insufficient to cover new aspects of the production process. Typical examples are potential model and processing errors when applying new processing steps such as machine learning methods, text mining etc.
Figure 1 shows a data pipeline for the scraping (ingesting) and processing OJA (Online Job Advertisements) data. Additionally, the figure shows – with no claim to completeness – important error sources and quality aspects.
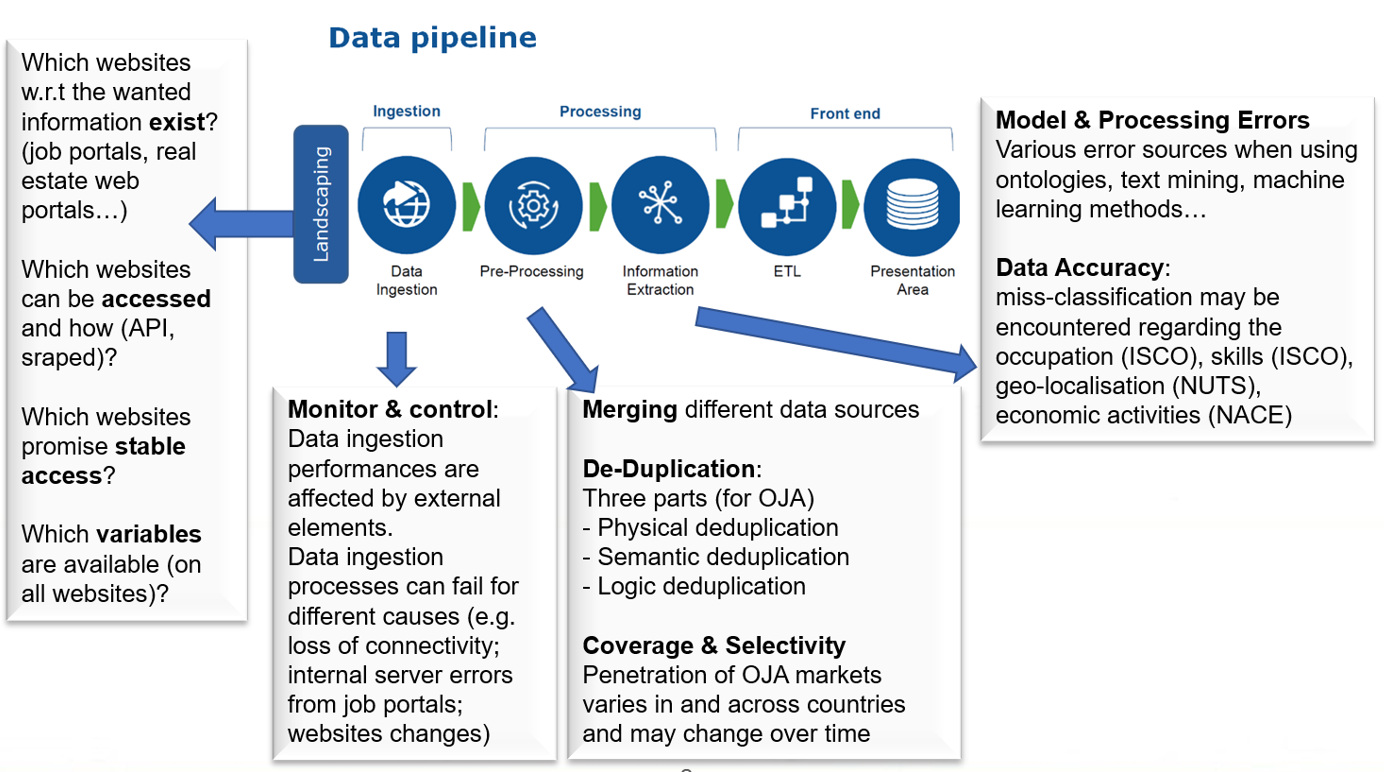
Figure 1 Data pipeline and new quality aspects
Landscaping
In this blog post, we want to focus on the beginning of the data pipeline: What is meant by “landscaping”, and which challenges have to be expected?
Within a company or organisation, the term “landscaping” is used for cataloguing and measurement of all the data within the company or organisation. Similarly, in the world of web-based data, landscaping refers to the cataloguing and measurement of all web-based data sources relevant to the topic of interest. Depending on the topic of interest, the effort of the landscaping exercise varies enormously: E.g., in the case of satellite data, all the needed data might be available on one single website. In the case of online job advertisements, real estate prices or price statistics, the great extent of existing websites – with varying market share, varying trustworthiness, varying legal and technical characteristics etc. – makes it necessary to select specific websites. In other cases, such as enterprise characteristics, all websites available should be scraped. An additional point to keep in mind is that not all units of interest (e.g. enterprises) may actually have/be found on a website.
Selection of websites
When it is necessary to select websites, it is of utter importance that this selection process does not happen arbitrarily. Especially when the comparability between different countries has to be guaranteed, the need for a standard tool for assessment and justification of data sources selection becomes obvious.
The partners of Work Package three, “New use cases”, have developed a checklist for assessing web data sources designed specifically for that purpose. It includes a list of characteristics of the website whose existence (absence respectively) is necessary for the assessment of the website as a suitable source for scraping.
This list of characteristics is subdivided into:
- Stop criteria (if one of the stop criteria is fulfilled, the website is rejected). Examples of these mostly technical stop criteria are whether a website uses a captcha or blocks robots.
- Minimal criteria (if not all of the minimum criteria are fulfilled, the website is rejected). Examples of these minimal criteria can be of technical nature (e.g. whether a web source offers a content filtering functionality relevant to the use case, whether the content of the web source has new content published within the last month), as well as content-wise nature (e.g. whether the number of ads on the web source is greater than a certain number)
- Mandatory variables (if not all listed mandatory variables can be found and scraped on the website, the website is rejected). These mandatory variables partly vary for each use case, but within a use case, they were agreed on and fixed by all use case partners. This guaranteed that all partners scraped comparable information. For the use case on "Characteristics of the real estate market", mandatory use case-specific variables were the price and the apartment type. Further, mandatory variables were the existence of a URL of the offer and an advertisement ID.
Further, the checklist consists of conditions whose fulfilment on the website is checked. The number of conditions fulfilled is added up; the higher the resulting score of a website, the better. The partners of WP Three decided on a threshold, or a number of the highest-ranked websites, to be scraped.
The list of conditions included:
- Existence of additional criteria, which are not mandatory but which increase the viability of the website
- Existence of optional variables to be found on the website, which provides additional information
Effect of selection of websites on quality
The stability of the sources themselves, as well as the stability of the scraping (ingestion) process, is the precondition for results of satisfying quality.
Even with stable access to web sources, it is a challenge to differentiate if an observed phenomenon (e.g. growth in the absolute number of scraped OJAs of a certain website) happens due to a phenomenon in the real-world (e.g. growth in the number of job vacancies) or due to a change in the website (e.g. the website becomes more popular and attracts thereby a higher number of OJA).
With unstable access to data sources, this differentiation becomes almost impossible. When sources suddenly vanish from a data set, indicators based on a combination of scraped data from different sources become more or less useless. When the scraping process is unstable, an observed decline or growth in the number of scraped ads loses significance.
The quality dimensions “accuracy and reliability” as well as “comparability and coherence” are all strongly negatively affected by the instability of the sources. Overall, statistical indicators based on unstable sources barely have any relevance because they are not clearly describing the actual real-world phenomenon.
Example of OJAs for Austria
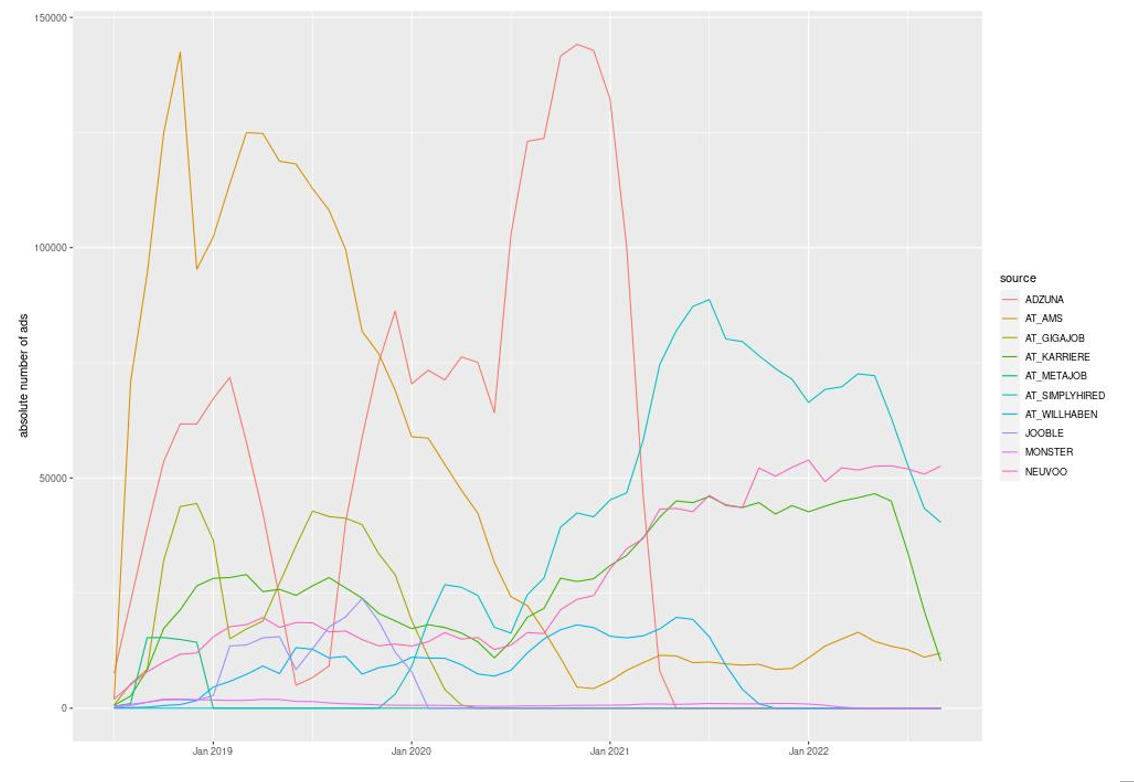
Figure 2 Absolute number of scraped OJAs for Austria for each of the ten most important sources
Looking at the absolute number of scraped OJAs from a dataset provided by the Web Intelligence Hub for Austria illustrates the problems mentioned earlier. Figure 2 shows the absolute number of scraped OJAs for each of the ten most important sources in the data set.
Two specific examples illustrate the before mentioned problems:
- The data source “ADZUNA” plays a very prominent role, especially during 2020. Partly more than 50% of all scraped OJAs came from this source. Access to this source stopped in the first months of 2021; thereby, an indicator for the whole time period, including “ADZUNA”, has barely any significance.
- The absolute number of ads scraped from the data source “AT_AMS”, standing for the Austrian public unemployment office (“Arbeitsmarktservice”), fell from a high level at the beginning of 2019 until the end of 2020, then stayed at a very low level. Comparing this observation with the information from the Austrian unemployment agency makes it clear that the reason for this decline does not correspond to the actual number of OJAs on their website. We do not know the real reason for the observed decline, but we assume that the reason are technical issues.
- The absolute number of ads scraped from the data source “AT_AMS”, standing for the Austrian public unemployment office (“Arbeitsmarktservice”), fell from a high level at the beginning of 2019 until the end of 2020, then stayed at a very low level. Comparing this observation with the information from the Austrian unemployment agency makes it clear that the reason for this decline does not correspond to the actual number of OJAs on their website. We do not know the real reason for the observed decline, but we assume that the reason are technical issues.
Authors: Magdalena Six, Alexander Kowarik, Statistik Austria
Published February 2023